In a recent post I showed the way I structure my apps, only three layers — API, Core (business logic), and Infrastructure (handling interactions with the database, cache, external services).
Architecture I Use in My Projects
Today I want to zoom in on the key difference between a layered and a clean architecture — dependency inversion.
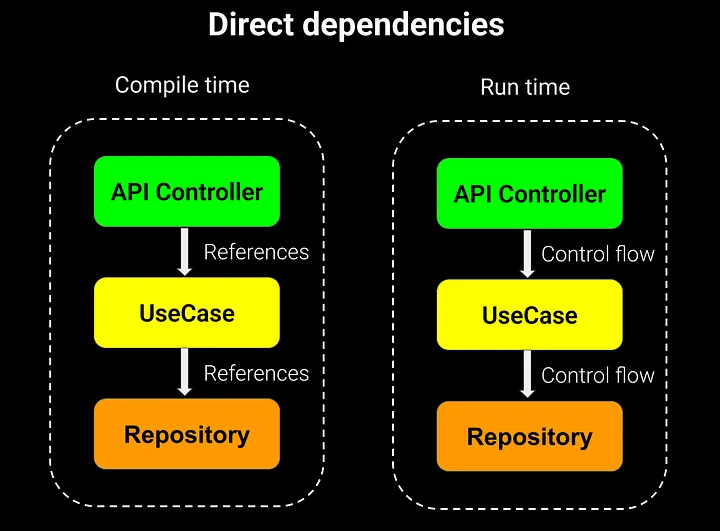
In a layered setup, the API calls methods on the Core class (UseCase), and Core calls methods on the Infrastructure class (Repository). The split already clarifies responsibilities, yet Core still knows concrete classes from Infrastructure, which makes the domain harder to isolate and test.
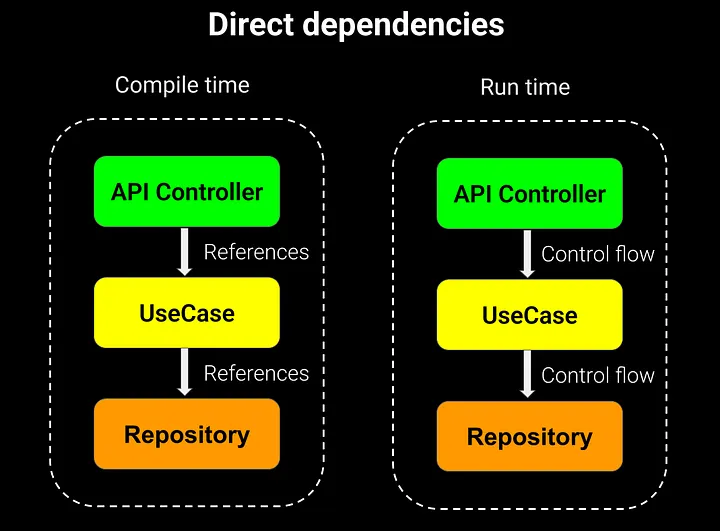
With dependency inversion, calls go through abstractions. Core depends on interfaces, while concrete classes are wired at run time. The control flow stays the same, but tests get easier — we plug in mocks and check the domain logic in isolation.
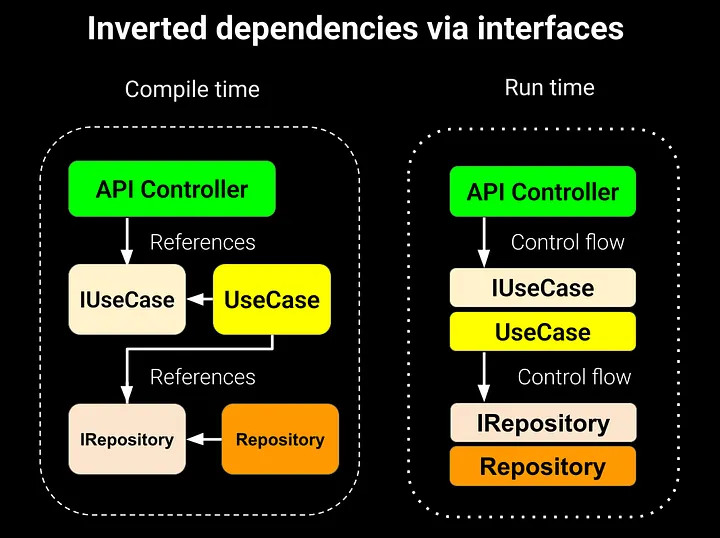
This principle is more than a nice-to-have. It sits at the heart of maintainable software, and it’s something you’ll often be asked about in interviews.
In summary, by inverting dependencies you keep your Core clean and testable, accelerating development and minimizing risk when requirements evolve.
Make dependency inversion a fundamental part of your design toolbox to ensure flexibility and resilience as your codebase grows.
For a deeper dive, I recommend reading: